یکی از مراحل کار با مدل مارکوف استفاده از پنجره لغزان یا اسلایدینگ ویندو هست. باید تمام داده ها رو هش کرد و جریان کلیک کاربران رو استخراج کرد. در ادامه در این خصوص و شیوه کار اسلایدینگ ویندو و شیوه پیش بینی توسط مدل مارکوف توضیحاتی می دم
پیاده سازی عمل هش کردن مجموعه ترین را با یک مثال تشریح می کنیم :
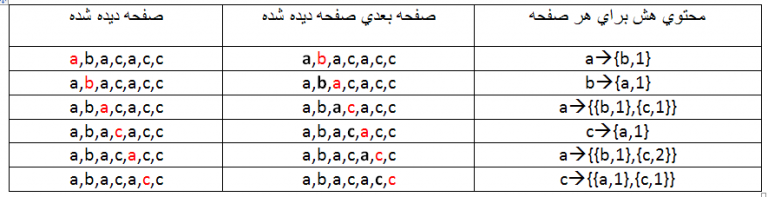
فرض کنید مجموعه ترین ما حاوی یک سشن به قرار زیر باشد :
a,b,a,c,a,c,c
به منظور هش کردن این مجموعه بر اساس گرم ها به این صورت عمل می شود.
باقی مطلب را در ادامه مطلب بخوانید.
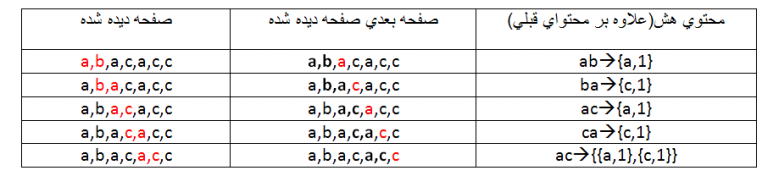
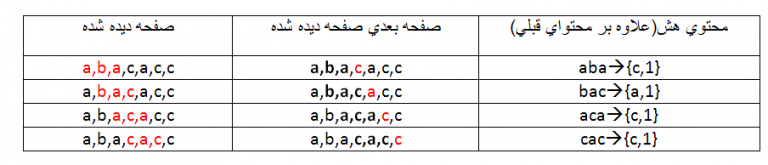
فرض کنید بخواهیم از مدل مارکوف مرتبه ۳ استفاده کنیم. در این صورت به شکل زیر عمل می کنیم.
در مرحله اول از مارکوف مرتبه اول استفاده می شود :
در مرحله دوم از مارکوف مرتبه دوم استفاده می شود :
در مرحله دوم از مارکوف مرتبه سوم استفاده می شود :
برای تمام مجموعه آموزشی این کار را انجام می دهیم.
دقت کنید که محتوی هش در سی شارپ به صورت زیر می باشد :
Key , List of value
مثلا برای داده های بالا یک لیستی از مقادیر داریم که درون ولیو هر کلید ذخیره می شود
شیوه پیشبینی صفحه بعدی به کمک این جدول
در این شیوه صفحه آخر هر سشن مجموعه تست را جدا کرده و صفحات یکی به آخر الی ایکس را به هش می دهیم. دقت کنید که ایکس همان بیشترین مرتبه مدل مارکوف می باشد.
حال اگر کلیدی با این مقدار وجود داشت ولیو آن را به عنوان خروجی بر می گردانیم
به عنوان مثال فرض کنید بخواهیم با مدل مارکوف مرتبه سوم پیش بینی انجام دهیم :
فرض کنید طول مجموعه تست به قرار زیر باشد :
x,b,a,x,a,b
مراحل کار به صورت زیر می باشد :
ابتدا صفحه آخر یعنی b را جدا می کنیم و با باقی عملیات پیش بینی انجام می شود. سپس خروجی را با b مقایسه می کنیم که آیا درست پیش بینی کردیم یا خیر :
حال برای هر سشن تست این کار را انجام می دهیم. به ازای هر پیش بیین صحیح، یک هیت و هر پیش بینی غلط یک میس می زنیم. خروجی نهایی مجموع هیت ها بخش بر کل تست ها می باشد.
برنامه این مورد آماده است و می تونید اون رو درخواست بدید.
سلام.وقت بخیر
مثالی که زدین ابتدا میاد ترین های رو هش میکنه و بعد با یه مثال تست صحت پیش بینی رو اندازه میگیره. پس نقش خوشه بندی محموعه ترین در فرایند پیش بینی چی هست؟ تشکر از وقتی که برای پاسخ ها میذارید
سلام
اول خواهش می کنم
دوم نگاه کنید خوشه بندی اول کار انجام می شه. شما یک مجموعه داده بزرگ دارید که باید برای کل این مجموعه داده یک ماتریس بزرگ درست بشه. وقتی خوشه بندی میکنیم اولا سشن های شبیه به هم می رن تو یک خوشه که باعث می شه صحت کار بهتر بشه ، در ثانی بجای تشکیل یک ماتریس بزرگ، یک ماتریس کوچک برای هر خوشه درست می کنیم پس از نظر فضایی هم به سیستم کمک می کنیم.
اما سوم از نظر سرعت هم سرعت کار بالا می ره.
با عرض سلام و وقت بخیر و ممنون از شما بابت کمک هاتون
سوالم اینه که محاسبه صحت مگه نباید توی قسمت تست انجام بشه؟ چرا برای داده های آموزشی صحت رو اندازه میگیریم؟؟
سلام
خواهش می کنم
بله در اصل محاسبه صحت باید در قسمت تست انجام بشه. من هم همینکار رو کردم. مثلا 50 درصد رو ترین در نظر گرفتم و 50 درصد رو تست.
نگاه کنید یک بار در فاز آموزش اومدم مثلا 50 درصد رو تست در نظر گرفتم و صحت رو بدست آوردم. اینها همه در فاز آموزش هست. دلیلش هم اینه که بتونم بهترین صحت رو بدست بیارم. یعنی در فاز ترین اومدم سیستم رو با تست کردن ترین کردم. بعد که بهترین لیبل مشخص شد، حالا وارد فاز تست شدم. برای راحتی کار نیامدم ایکس عدد از هر خوشه بکنم و جدا بزارم برای تست ، بلکه اومدم ایکس درصد از اول هر خوشه رو در نظر گرفتم به عنوان تست.
امیدوارم شبهه دیگری پیش نیامده باشه . اگر آمد بفرمایید تا صحبت کنیم.
سلام. وقتتون بخیر
من چند تا سوال برام پیش اومد؛ ببخشید طولانی شده
توی شباهت سنجی کسینوسی، دو به دو نشست ها رو با هم مقایسه میکنیم و برای اینکه حجم ماتریس کلیک استریم کم بشه، شما در پاورپوینت مقاله تون گفتین فقط اندیس صفحات رو ذخیره میکنیم. اونوقت مقایسه چطور انجام میشه؟ مگه مقایسه نباید بر اساس تعداد دفعات مشاهده صفحه انجام بشه؟ یعنی هم اندیس هم تعداد دفعات مشاهده؟
توی ویدیو مقاله تون، پیش بینی با مارکوف همه مراتب رو گفتین همون مرتبه 13 منظورمون هست. پس یعنی از مرتبه 12 به ترتیب تا مرتبه 1 پیش بینی نمیکنه؟
برای اینکه بتونیم با مارکوف پیش بینی انجام بدیم باید قبلش داده ها رو هش کرده باشیم تا احتمالات بدست بیاد. سیستم چه موقع شروع به هش کردن سشن ها میکنه؟
سلام
عاقبت شما بخیر
دو تا ماتریس داریم. یکی کلیک استریم هست که تعداد کلیک ها ذخیره می شه و یکی یک ماتریس دیگه که اندیس هر خانه پر در هر سطر رو ذخیره می کنه. حالا از ماتریس دوم استفاده می کنیم و برای پردازش هامون سریع به خانه های پر ماتریس اول مراجعه می کنیم.
سوال دوم :
از مرتبه سیزده شروع می کنیم به مرتبه یک می رسیم. هر مرتبه ای که بیشترین صحت را داشت انتخاب می کنیم و همیشه با آن پیش بینی می کنیم. فرض کنید یک خوشه مرتبه 10 به عنوان بهترین مرتبه شناخته شده باشه، میایم اول ده تا صفحه از سشن رو می کنیم و می دیم به اون، اگر چیزی به خروجی داد که همون رو در نظر می گیریم در غیر اینصورت یک مرتبه کم می کنیم و همینطور میایم پایین تا یک خروجی به ما بده
سوال سوم:
شما باید تعداد کلیک های هر فرد رو در بیارید. حالا چه هش کنید چه ماتریس تشکیل بدید و .....
سلام وقت بخیر
شما که در بالا در مورد نحوه انتخاب صفحه بعدی توضیح دادید و در مرحله تست در جدول هش به دو احتمال مساوی رسیدید و یکی را به خروجی فرستادید من در جدول هش که تشکیل دادید مورد دیگری بعد از a را دیدم یعنی بعد از a
{{b,1}, {c,2}} چرا این رو که احتمال دیده شدن c زیادتر است در نظر نگرفتید؟
سوال دیگه اینکه ما از این جدول هش استفاده می کنیم و ماتریس تشکیل می دیم؟ یا همین جدول هش واسه پیشنهاد کافیه و نیازی به ماتریسی که نشون میده بعد از هر صفحه چند بار یا با چه احتمالی صفحه بعدی دیده میشه نیاز نیست؟
ممنون از وقتی که می ذارین. با تشکر
سلام
در حالت کلی وقتی میخوایم صفحه ی بعدی رو پیش بینی کنیم اونی که احتمالش بیشتر هست رو بر میداریم، با توجه به اینکه بعد از صفحه a تنها دو {{b,1}, {c,2}}حالت در هش موجود است، صفحه ی پیشنهادی c خواهد بود،
اما در رابطه با سوال دومتون،بستگی به ایده شما داره، اگه با مراتب ساده مارکوف برین مثلا مارکوف مرتبه دو،نیازی نیست که ماتریس تشکیل بدین و با همون جدول هش کارتون راه می افته،به عنوان مثال برای پیاده سازی ایده یکی از کاربران سایت که در زمینه مارکوف بود و نتیجه ی خوبی هم داد،نیاز به تشکیل ماتریس انتقال بود، پس این کار بستگی به ایدتون داره
با سلام و وقت بخیر
اگر با توجه به اینکه مدل مارکوف با همه مراتب دارای تعداد حالات بسیار زیاد می باشد و این نیز یکی از معایب آن به حساب می آید، چطور می توان روشی ارائه کرد که خطای هر حالت در مجموعه اعتبار سنجی تخمین زده شود و اگر یک حالت از مرتبه بالاتر، خطای بیشتری در مقایسه با حالت های مشابه از مرتبه پایین تر داشت حذف شود ؟!
ممنون میشوم این را با مثال برایم توضیح دهید.
تشکـــــر
با سلام
مقاله زیر رو حتما بخونید اونجا خیلی بهتون کمک خواهد شد مثال هم داره
این کاری که شما میخواین ایده ی اصلی این مقاله است
http://dl.acm.org/citation.cfm?id=990304
باز اگه مشکلی داشتین مطرح بفرمایید تا جایی که امکان داره توضیح داده خواهد شد
با سلام می خواستم بدونم در خصوص مدل مارکوف پیش بینی کننده وب آیا مقاله ای هست تا بر اساس وزن صفحات (مثل میزان مدت زمان مشاهده سایت توسط کاربر ) توجه بیشتری انجام بشه
چرا که در این روش ها کیفیت پیشنهاد تا حدی بهبود می یابد چرا که به سلیقه کاربر توجه بیشتری می شود ممنون می شم اگه توضیح بیشتری بدهید یا مقاله سا پایان نامه ای را معرفی کنید
با سلام
دوتا مقاله براتون ارسال شد
ببنید به درتون میخوره
در رابطه با پارامتر زمان چند نفر از کاربران سایت کار کردن
برخی با انجمنی کار کردن، دو سه نفرشونم با مارکوف
دو نفرشون اگه به این زودی دفاع کردن قطعا پایان نامشون در اختیارتون می زارن تا استفاده کنید
باز اگه سوالی دارین مطرح بفرمایید در حد توان پاسخ داده خواهد شد
با احترام
سلام می خواستم بدونم بکارگیری مدل مارکوف با روش LWLR و LWHR چی هست . چه تفاوتی با روشی که توضیح دادید دارد سوال دوم شما در مقالتون مرتبه 25 مارکوف و 13 خوشه رو در نظر گرفتید چطور به این عدد رسیدید ممنون از راهنمایی شما
سلام
هر کدوم کاربرد خودشون رو دارن
هدف این بود که بتونم بهترین صحت رو در بیارم بخاطر همین دو حالت رو انتخاب کردم
سوال دومتون هم جوابش اینه که با تست کردن به این نتیجه رسیدم
سلام ممنون از پاسخگویی شما روش LWLR و LWHR مخفف چی هست و چه فرقی با مدل مارکوف داره من جواب این سوال رو نتونستم از پاسخ شما بدست بیارم ممنونم و سپاسگذار
Label with Low Rank(LWLR) مخفف LWLR، هستش یعنی تو این روش برچسبی که برای خوشه با استفاده از مدل مارکوف همه مراتب زده میشه بر اساس رنک یک هست، قبلا هم راجب رنک بحث شده
روش دوم كه آن را Label with High Rank(LWHR) مي ناميم صحت تمام مراتب مدل ماركوف را با رتبه ده(اگر يكي از ده صفحه ي محتمل كه به عنوان صفحه بعدي كاربر پيش بيني مي شود، درست پيش بيني شده باشد، مي گوييم براي آن تراكنش توانستيم صفحه بعدي كاربر را درست پيش بيني كنيم) براي تمام خوشه ها بدست آورده و بيشترين آنها را به عنوان برچسب براي آن خوشه در نظر مي گيريم. براي اين منظور تمام مراتب مدل ماركوف را به خوشه ها اعمال مي كنيم با اين تفاوت كه در محاسبه صحت هر خوشه، صحت پيش بيني آن خوشه را با رتبه ده بدست مي آوريم. در نتيجه برچسب نهايي، برچسبي مي باشد كه بيشترين صحت را در يكي از مراتب مدل ماركوف با رتبه ده از آن ما كند.
سلام .
اون دو مقاله ای که در رابطه با مدل مارکوف پیش بینی کننده صفحات وب هستند و برای دوستمون ارسالشان کردید را اگر امکان دارد برای بنده هم ارسال کنید. نیاز خیلی فوری دارم. با تشکر فراوان
سلام
در صورت تمایل به ایمیلم Research.moghimi@gmail.com ایمیل بزنید یا از طریق آی دی تلگرام بنده Research_moghimi@ برای بیان جزئیات با شما در ارتباط خواهم بود
با سلام
sliding windows اوصلا در سیستم های توصیه گری که بیش از یک صفحه به کاربر صفحه پیشنهاد میدن استفاده میشه، مثلا سیستم های توصیه گری که با استفاده از قوانین انجمنی چند صفحه رو پیشنهاد میدن
با مطالعه تو مقالات سیستم توصیه گر با استفاده از قوانین انجمنی می تونید بیشتر تو این زمینه اطلاعات بدست بیارید
سلام
موضوع پايان نامه بنده درخصوص بهبود صفحات سفارش شده به كاربر توسط موتور جستجو هستش كه ميخوام با استفاده از مدل ماركوف دقت پيش بيني صفحات رو بالا بببرم. ممنون ميشم اگه مطلب يا مقاله اي در اين خصوص داريد واسم ايميل بزنين.
سپاسگذارم
سلام
وقتی با مارکوف مرتبه 3 قرار عمل پیش بینی انجام بشه..اگه ناموفق بود مرتبه رو کم می کنیم با مرتبه دو بعد هم یک؟
یا فقط همون مرتبه3؟
چون بعضی مقالات اومده دیتاست رو توی مارکوف مثلا 2و3و4و5و6 جدا نتایج رو نشون داده



سلام.وقت بخیر
مثالی که زدین ابتدا میاد ترین های رو هش میکنه و بعد با یه مثال تست صحت پیش بینی رو اندازه میگیره. پس نقش خوشه بندی محموعه ترین در فرایند پیش بینی چی هست؟ تشکر از وقتی که برای پاسخ ها میذارید
سلام
اول خواهش می کنم
دوم نگاه کنید خوشه بندی اول کار انجام می شه. شما یک مجموعه داده بزرگ دارید که باید برای کل این مجموعه داده یک ماتریس بزرگ درست بشه. وقتی خوشه بندی میکنیم اولا سشن های شبیه به هم می رن تو یک خوشه که باعث می شه صحت کار بهتر بشه ، در ثانی بجای تشکیل یک ماتریس بزرگ، یک ماتریس کوچک برای هر خوشه درست می کنیم پس از نظر فضایی هم به سیستم کمک می کنیم.
اما سوم از نظر سرعت هم سرعت کار بالا می ره.
با عرض سلام و وقت بخیر و ممنون از شما بابت کمک هاتون
سوالم اینه که محاسبه صحت مگه نباید توی قسمت تست انجام بشه؟ چرا برای داده های آموزشی صحت رو اندازه میگیریم؟؟
سلام
خواهش می کنم
بله در اصل محاسبه صحت باید در قسمت تست انجام بشه. من هم همینکار رو کردم. مثلا 50 درصد رو ترین در نظر گرفتم و 50 درصد رو تست.
نگاه کنید یک بار در فاز آموزش اومدم مثلا 50 درصد رو تست در نظر گرفتم و صحت رو بدست آوردم. اینها همه در فاز آموزش هست. دلیلش هم اینه که بتونم بهترین صحت رو بدست بیارم. یعنی در فاز ترین اومدم سیستم رو با تست کردن ترین کردم. بعد که بهترین لیبل مشخص شد، حالا وارد فاز تست شدم. برای راحتی کار نیامدم ایکس عدد از هر خوشه بکنم و جدا بزارم برای تست ، بلکه اومدم ایکس درصد از اول هر خوشه رو در نظر گرفتم به عنوان تست.
امیدوارم شبهه دیگری پیش نیامده باشه . اگر آمد بفرمایید تا صحبت کنیم.
سلام. وقتتون بخیر
من چند تا سوال برام پیش اومد؛ ببخشید طولانی شده
توی شباهت سنجی کسینوسی، دو به دو نشست ها رو با هم مقایسه میکنیم و برای اینکه حجم ماتریس کلیک استریم کم بشه، شما در پاورپوینت مقاله تون گفتین فقط اندیس صفحات رو ذخیره میکنیم. اونوقت مقایسه چطور انجام میشه؟ مگه مقایسه نباید بر اساس تعداد دفعات مشاهده صفحه انجام بشه؟ یعنی هم اندیس هم تعداد دفعات مشاهده؟
توی ویدیو مقاله تون، پیش بینی با مارکوف همه مراتب رو گفتین همون مرتبه 13 منظورمون هست. پس یعنی از مرتبه 12 به ترتیب تا مرتبه 1 پیش بینی نمیکنه؟
برای اینکه بتونیم با مارکوف پیش بینی انجام بدیم باید قبلش داده ها رو هش کرده باشیم تا احتمالات بدست بیاد. سیستم چه موقع شروع به هش کردن سشن ها میکنه؟
سلام
عاقبت شما بخیر
دو تا ماتریس داریم. یکی کلیک استریم هست که تعداد کلیک ها ذخیره می شه و یکی یک ماتریس دیگه که اندیس هر خانه پر در هر سطر رو ذخیره می کنه. حالا از ماتریس دوم استفاده می کنیم و برای پردازش هامون سریع به خانه های پر ماتریس اول مراجعه می کنیم.
سوال دوم :
از مرتبه سیزده شروع می کنیم به مرتبه یک می رسیم. هر مرتبه ای که بیشترین صحت را داشت انتخاب می کنیم و همیشه با آن پیش بینی می کنیم. فرض کنید یک خوشه مرتبه 10 به عنوان بهترین مرتبه شناخته شده باشه، میایم اول ده تا صفحه از سشن رو می کنیم و می دیم به اون، اگر چیزی به خروجی داد که همون رو در نظر می گیریم در غیر اینصورت یک مرتبه کم می کنیم و همینطور میایم پایین تا یک خروجی به ما بده
سوال سوم:
شما باید تعداد کلیک های هر فرد رو در بیارید. حالا چه هش کنید چه ماتریس تشکیل بدید و .....
سلام وقت بخیر
شما که در بالا در مورد نحوه انتخاب صفحه بعدی توضیح دادید و در مرحله تست در جدول هش به دو احتمال مساوی رسیدید و یکی را به خروجی فرستادید من در جدول هش که تشکیل دادید مورد دیگری بعد از a را دیدم یعنی بعد از a
{{b,1}, {c,2}} چرا این رو که احتمال دیده شدن c زیادتر است در نظر نگرفتید؟
سوال دیگه اینکه ما از این جدول هش استفاده می کنیم و ماتریس تشکیل می دیم؟ یا همین جدول هش واسه پیشنهاد کافیه و نیازی به ماتریسی که نشون میده بعد از هر صفحه چند بار یا با چه احتمالی صفحه بعدی دیده میشه نیاز نیست؟
ممنون از وقتی که می ذارین. با تشکر
سلام
در حالت کلی وقتی میخوایم صفحه ی بعدی رو پیش بینی کنیم اونی که احتمالش بیشتر هست رو بر میداریم، با توجه به اینکه بعد از صفحه a تنها دو {{b,1}, {c,2}}حالت در هش موجود است، صفحه ی پیشنهادی c خواهد بود،
اما در رابطه با سوال دومتون،بستگی به ایده شما داره، اگه با مراتب ساده مارکوف برین مثلا مارکوف مرتبه دو،نیازی نیست که ماتریس تشکیل بدین و با همون جدول هش کارتون راه می افته،به عنوان مثال برای پیاده سازی ایده یکی از کاربران سایت که در زمینه مارکوف بود و نتیجه ی خوبی هم داد،نیاز به تشکیل ماتریس انتقال بود، پس این کار بستگی به ایدتون داره
با سلام و وقت بخیر
اگر با توجه به اینکه مدل مارکوف با همه مراتب دارای تعداد حالات بسیار زیاد می باشد و این نیز یکی از معایب آن به حساب می آید، چطور می توان روشی ارائه کرد که خطای هر حالت در مجموعه اعتبار سنجی تخمین زده شود و اگر یک حالت از مرتبه بالاتر، خطای بیشتری در مقایسه با حالت های مشابه از مرتبه پایین تر داشت حذف شود ؟!
ممنون میشوم این را با مثال برایم توضیح دهید.
تشکـــــر
با سلام
مقاله زیر رو حتما بخونید اونجا خیلی بهتون کمک خواهد شد مثال هم داره
این کاری که شما میخواین ایده ی اصلی این مقاله است
http://dl.acm.org/citation.cfm?id=990304
باز اگه مشکلی داشتین مطرح بفرمایید تا جایی که امکان داره توضیح داده خواهد شد
با سلام می خواستم بدونم در خصوص مدل مارکوف پیش بینی کننده وب آیا مقاله ای هست تا بر اساس وزن صفحات (مثل میزان مدت زمان مشاهده سایت توسط کاربر ) توجه بیشتری انجام بشه
چرا که در این روش ها کیفیت پیشنهاد تا حدی بهبود می یابد چرا که به سلیقه کاربر توجه بیشتری می شود ممنون می شم اگه توضیح بیشتری بدهید یا مقاله سا پایان نامه ای را معرفی کنید
با سلام
دوتا مقاله براتون ارسال شد
ببنید به درتون میخوره
در رابطه با پارامتر زمان چند نفر از کاربران سایت کار کردن
برخی با انجمنی کار کردن، دو سه نفرشونم با مارکوف
دو نفرشون اگه به این زودی دفاع کردن قطعا پایان نامشون در اختیارتون می زارن تا استفاده کنید
باز اگه سوالی دارین مطرح بفرمایید در حد توان پاسخ داده خواهد شد
با احترام
سلام می خواستم بدونم بکارگیری مدل مارکوف با روش LWLR و LWHR چی هست . چه تفاوتی با روشی که توضیح دادید دارد سوال دوم شما در مقالتون مرتبه 25 مارکوف و 13 خوشه رو در نظر گرفتید چطور به این عدد رسیدید ممنون از راهنمایی شما
سلام
هر کدوم کاربرد خودشون رو دارن
هدف این بود که بتونم بهترین صحت رو در بیارم بخاطر همین دو حالت رو انتخاب کردم
سوال دومتون هم جوابش اینه که با تست کردن به این نتیجه رسیدم
سلام ممنون از پاسخگویی شما روش LWLR و LWHR مخفف چی هست و چه فرقی با مدل مارکوف داره من جواب این سوال رو نتونستم از پاسخ شما بدست بیارم ممنونم و سپاسگذار
Label with Low Rank(LWLR) مخفف LWLR، هستش یعنی تو این روش برچسبی که برای خوشه با استفاده از مدل مارکوف همه مراتب زده میشه بر اساس رنک یک هست، قبلا هم راجب رنک بحث شده
روش دوم كه آن را Label with High Rank(LWHR) مي ناميم صحت تمام مراتب مدل ماركوف را با رتبه ده(اگر يكي از ده صفحه ي محتمل كه به عنوان صفحه بعدي كاربر پيش بيني مي شود، درست پيش بيني شده باشد، مي گوييم براي آن تراكنش توانستيم صفحه بعدي كاربر را درست پيش بيني كنيم) براي تمام خوشه ها بدست آورده و بيشترين آنها را به عنوان برچسب براي آن خوشه در نظر مي گيريم. براي اين منظور تمام مراتب مدل ماركوف را به خوشه ها اعمال مي كنيم با اين تفاوت كه در محاسبه صحت هر خوشه، صحت پيش بيني آن خوشه را با رتبه ده بدست مي آوريم. در نتيجه برچسب نهايي، برچسبي مي باشد كه بيشترين صحت را در يكي از مراتب مدل ماركوف با رتبه ده از آن ما كند.
سلام. خسته نباشید و تشکر فراوان از ارائه مطالب خوبتان.
میشه نحوه ی تشخیص نشست های کاربران در وب را توضیح دهید.
سلام
در سایت مقاله ای با عنوان پیش پردازش هست بخونید
سلام .
اون دو مقاله ای که در رابطه با مدل مارکوف پیش بینی کننده صفحات وب هستند و برای دوستمون ارسالشان کردید را اگر امکان دارد برای بنده هم ارسال کنید. نیاز خیلی فوری دارم. با تشکر فراوان
سلام
در صورت تمایل به ایمیلم Research.moghimi@gmail.com ایمیل بزنید یا از طریق آی دی تلگرام بنده Research_moghimi@ برای بیان جزئیات با شما در ارتباط خواهم بود
باسلام میشه لطفاموارد استفاده sliding windows روهم بگین
با سلام
sliding windows اوصلا در سیستم های توصیه گری که بیش از یک صفحه به کاربر صفحه پیشنهاد میدن استفاده میشه، مثلا سیستم های توصیه گری که با استفاده از قوانین انجمنی چند صفحه رو پیشنهاد میدن
با مطالعه تو مقالات سیستم توصیه گر با استفاده از قوانین انجمنی می تونید بیشتر تو این زمینه اطلاعات بدست بیارید
سلام
موضوع پايان نامه بنده درخصوص بهبود صفحات سفارش شده به كاربر توسط موتور جستجو هستش كه ميخوام با استفاده از مدل ماركوف دقت پيش بيني صفحات رو بالا بببرم. ممنون ميشم اگه مطلب يا مقاله اي در اين خصوص داريد واسم ايميل بزنين.
سپاسگذارم
سلام
همه چیز دو طرفه است. شما هم هر چی مطلب در این خصوص پیدا می کنید برای افزایش آگاهی کاربران در اینترنت قرار بدید
سلام
وقتی با مارکوف مرتبه 3 قرار عمل پیش بینی انجام بشه..اگه ناموفق بود مرتبه رو کم می کنیم با مرتبه دو بعد هم یک؟
یا فقط همون مرتبه3؟
چون بعضی مقالات اومده دیتاست رو توی مارکوف مثلا 2و3و4و5و6 جدا نتایج رو نشون داده
سلام
بله ابتدا سه بعد دو و بعد یک
اون که اومده جدا نشون داده می خواسته شیوه رفتار مارکوف رو بررسی کنه در واقع در گرم های مختلف بررسیش کرده