



شکل ۴: شباهت بین دو خوشه در روش Single-Link برابر است با کمترین فاصله بین دادههای دو خوشه
مثال: در این قسمت سعی شده است تا در مثالی با فرض داشتن ۶ نمونه داده و ماتریس فاصله بین آنها که در جدول ۱ نشانداده شده است، نحوه اعمال روش خوشهبندی Single-Link بهتر تشریح شود
جدول ۱: ماتریس فاصله بین ۶ نمونه داده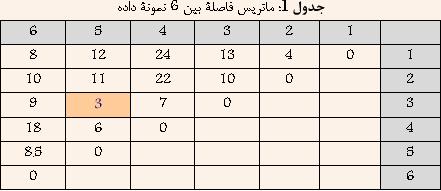
در ابتدا هر داده به عنوان یک خوشه در نظر گرفته میشود و یافتن نزدیکترین خوشه در واقع یافتن کمترین فاصله بین دادههای بالا خواهد بود. با توجه به جدول ۱ مشخص است که دادههای ۳ و ۵ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با کمترین فاصله بین ۳ و یا ۵ از سایر خوشهها. نتیجه در جدول ۲ نشان داده شده است.
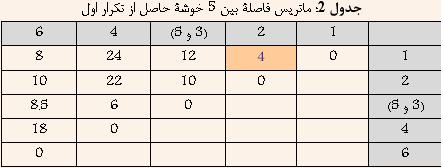
با توجه به جدول ۲ مشخص است که دادههای ۱ و ۲ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با کمترین فاصله بین ۱ و یا ۲ از سایر خوشهها. نتیجه در جدول ۳ نشان داده شده است.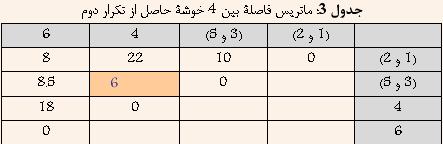
با توجه به جدول ۳ مشخص است که خوشههای (۳ و ۵) و ۴ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با کمترین فاصله بین (۳ و ۵) و یا ۴ از سایر خوشهها. نتیجه در جدول ۴ نشان داده شده است.
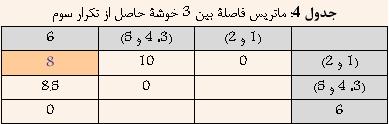
با توجه به جدول ۴ مشخص است که خوشههای (۱ و ۲) و ۶ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با کمترین فاصله بین (۱ و ۲) و یا ۶ از سایر خوشهها. نتیجه در جدول ۵ نشان داده شده است.
در نهایت این دو خوشه حاصل ا هم ترکیب میشوند. نتیجه در دندوگرام شکل ۵ نشان داده شده است.


شکل ۶: شباهت بین دو خوشه در روش Complete-Link برابر است با بیشترین فاصله بین دادههای دو خوشه.
مثال: در این قسمت سعی شده است تا در مثالی با فرض داشتن ۶ نمونه داده و ماتریس فاصله بین آنها که در جدول ۶ نشان داده شده است، نحوه اعمال روش خوشهبندی Complete-Link بهتر تشریح شود.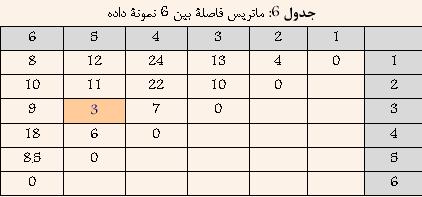
در ابتدا هر داده به عنوان یک خوشه در نظر گرفته میشود و یافتن نزدیکترین خوشه در واقع یافتن کمترین فاصله بین دادههای بالا خواهد بود. با توجه به جدول ۶ مشخص است که دادههای ۳ و ۵ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین ۳ و یا ۵ از سایر خوشهها. نتیجه در جدول ۷ نشان داده شده است.
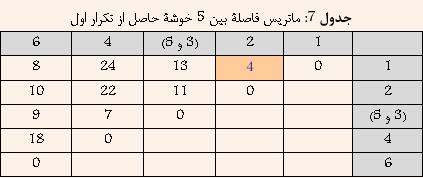
با توجه به جدول ۷ مشخص است که دادههای ۱ و ۲ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین ۱ و یا ۲ از سایر خوشهها. نتیجه در جدول ۸ نشان داده شده است.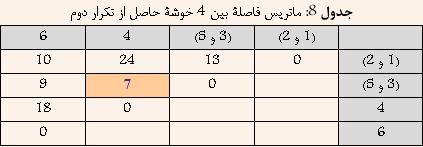
با توجه به جدول ۸ مشخص است که خوشههای (۳ و ۵) و ۴ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین (۳ و ۵) و یا ۴ از سایر خوشهها. نتیجه در جدول ۹ نشان داده شده است.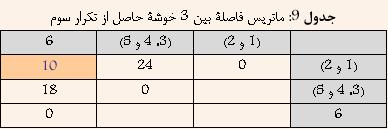
با توجه به جدول ۹ مشخص است که خوشههای (۱ و ۲) و ۶ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین (۱ و ۲) و یا ۶ از سایر خوشهها. نتیجه در جدول ۱۰ نشان داده شده است.
در نهایت این دو خوشه حاصل ا هم ترکیب میشوند. نتیجه در دندوگرام شکل ۷ نشان داده شده است.
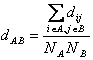

شکل ۸: شباهت بین دو خوشه در روش Average-Link برابر است با میانگین فاصله بین دادههای دو خوشه
مثال: در این قسمت سعی شده است تا در مثالی با فرض داشتن ۶ نمونه داده و ماتریس فاصله بین آنها که در جدول ۱۱ نشان داده شده است، نحوه اعمال روش خوشهبندی Average-Link بهتر تشریح شود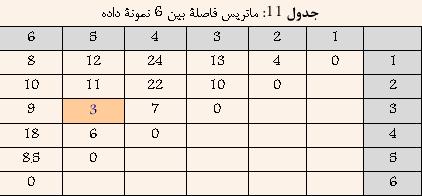
در ابتدا هر داده به عنوان یک خوشه در نظر گرفته میشود و یافتن نزدیکترین خوشه در واقع یافتن کمترین فاصله بین دادههای بالا خواهد بود. با توجه به جدول ۱۱ مشخص است که دادههای ۳ و ۵ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با میانگین فاصله بین ۳ و ۵ از سایر خوشهها. نتیجه در جدول ۱۲ نشان داده شده است.
با توجه به جدول ۱۲ مشخص است که دادههای ۱ و ۲ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین ۱ و یا ۲ از سایر خوشهها. نتیجه در جدول ۱۳ نشان داده شده است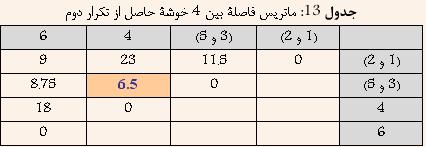
با توجه به جدول ۱۳ مشخص است که خوشههای (۳ و ۵) و ۴ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین (۳ و ۵) و یا ۴ از سایر خوشهها. نتیجه در جدول ۱۴ نشان داده شده است.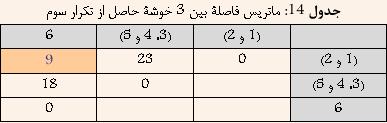
با توجه به جدول ۱۴ مشخص است که خوشههای (۱ و ۲) و ۶ کمترین فاصله را دارا هستند. و در نتیجه آنها را با هم ترکیب کرده و خوشه جدیدی حاصل میشود که فاصله آن از سایر خوشهها برابر است با بیشترین فاصله بین (۱ و ۲) و یا ۶ از سایر خوشهها. نتیجه در جدول ۱۵ نشان داده شده است.
در نهایت این دو خوشه حاصل ا هم ترکیب میشوند. نتیجه در دندوگرام شکل ۹ نشان داده شده است.


اغلب الگوریتم های خوشهبندی سلسله مراتبی را به نحوی میتوان گسترش یافته الگوریتم خوشهبندی Single-Link در نظر گرفت. تفاوت روش های مختلف در نحوه محاسبه ماتریس تشابه یا عدم تشابه (Dissimilaritye) آنها است. فرمولی بازگشتی به نام فرمول Lance-Williams تعریف شده است که عدمتشابه بین خوشه k و خوشه حاصل از پیوند خوشههای i و j را بیان میکند:

که پارامترهای ai، b و c بیان کننده نوع روش خوشهبندی هستند و در جدول ۱۶ مقادیر مربوط به چند روش آورده شده است:
سلام آقای مهندس
وقت بخیر
اگر ممکن در مورد بردار میانگین خوشه ها توضیحی بفرمایید. نحوه ی به دست اوردن آن.
ممنون از لطف شما
با سلام
ببینید بردار میانگین یعنی میانگین مجموعه ای از اطلاعات خطی
مثلا فرض کنید داریم
1,2,3,1,1,1,2
2,3,4,2,2,3,4
1,1,1,1,1,1,0
بردار میانگین این سه می شه
4/3,6/3,8/3,...
حالا در بحث خوشه بندی هم مطرح می شه این موضوع که میان بردار میانگین تولید می کنن برای برخی مقاصد و ممکنه بیش از یک بردار میانگین تولید کنید
یادمه یکی از مشتریانم اومد دیتاستش رو به بخش هایی تقسیم کرد و برای هر بخش بردار میانگین گرفت و از اونها برای خوشه بندی خودش استفاده کرد
سلام اقای مهندس
وقت بخیر
لطفا درباره روش وارد سلسله مراتب تجمعی بیشتر توضیح فرمایید.
ممنون میشم از لطف شما
با سلام
بخاطر دیرکرد عذر می خام
ببینید الگوریتم وارد اصل و بناش همون اگلومرتیو هست. در خصوص اگلومرتیو یا agglomerative قبلا صحبت کردیم و در فروشگاه هم یک نمونه پیاده سازیش وجود داره می تونید دانلود کنید
اما تغییری که وارد داره نسبت به الگوریتم اگلو اینه که موقع مرج کردن در اگلو شرط خاصی مطرح نیست مگر همجواری ولی در این الگوریتم باید برای مرج کردن دو خوشه اول به این نتیجه برسیم که این دو خوشه که دارن مرج میشن حتما بهینه ترین دو خوشه ای هستن که دارن مرج میشن
یعنی یک کلاستر در صورتی با کلاستر دیگه مرج میشه گه گزینه ای بهتر از اون کلاستر برای مرج نداشته باشیم
سلام
ببخشید جناب مقیمی امکان داره در ارتباط بافرمول ها و مکانیزم روش Ward در خوشه بندی سلسله مراتبی بیشتر توضیح دهید
با سلام
بخاطر دیرکرد عذر می خام
ببینید الگوریتم وارد اصل و بناش همون اگلومرتیو هست. در خصوص اگلومرتیو یا agglomerative قبلا صحبت کردیم و در فروشگاه هم یک نمونه پیاده سازیش وجود داره می تونید دانلود کنید
اما تغییری که وارد داره نسبت به الگوریتم اگلو اینه که موقع مرج کردن در اگلو شرط خاصی مطرح نیست مگر همجواری ولی در این الگوریتم باید برای مرج کردن دو خوشه اول به این نتیجه برسیم که این دو خوشه که دارن مرج میشن حتما بهینه ترین دو خوشه ای هستن که دارن مرج میشن
یعنی یک کلاستر در صورتی با کلاستر دیگه مرج میشه گه گزینه ای بهتر از اون کلاستر برای مرج نداشته باشیم
با سلام ووقت بخیر
اگه ممکن میخواستم درمورد خوشه بندی سلسله مراتبی centroid-linkage و فرمول آن توضیحی بفرمایید
تشکر
با سلام
ببینید این روش کلا با بردار میانه کار میکنه. شما بردار میانه دو تا ارایه از ابجکت ها رو در میارید مثلا میشه دو تا ارایه 2,3,5 و اونیکی هم یه چیز دیگه
حالا توی روش های سلسله مراتبی میاد اون دو تا وکتوری که بردار میانشون به هم نزدیکتر باشه مثلا به کمک فاصله اقلیدوسی رو میزاریم توی یه خوشه
امیدوارم خوب توضیح داده باشم.
ببینید بزارید بجای ماهی سرخ کرده به شما ماهیگیری یاد بدم. یکی از علمای بزرگ یعنی علامه جوادی عاملی می فرمایند اصول رو یاد بگیرید و از یادگیری مصادیق پرهیز کنید. سعی کنید اصول خوشه بندی سلسله مراتبی رو یاد بگیرید. باقی اون رو اومدن دماغش رو کج کردن و یا دهنش رو عوض کردن
با سلام و وقت بخیر
اگه ممکن در مورد خوشه بندی centroid linkage با یه مثال عددی توضیح بدین
تشکر
با سلام
ببینید این روش کلا با بردار میانه کار میکنه. شما بردار میانه دو تا ارایه از ابجکت ها رو در میارید مثلا میشه دو تا ارایه 2,3,5 و اونیکی هم یه چیز دیگه
حالا توی روش های سلسله مراتبی میاد اون دو تا وکتوری که بردار میانشون به هم نزدیکتر باشه مثلا به کمک فاصله اقلیدوسی رو میزاریم توی یه خوشه
امیدوارم خوب توضیح داده باشم.
ببینید بزارید بجای ماهی سرخ کرده به شما ماهیگیری یاد بدم. یکی از علمای بزرگ یعنی علامه جوادی عاملی می فرمایند اصول رو یاد بگیرید و از یادگیری مصادیق پرهیز کنید. سعی کنید اصول خوشه بندی سلسله مراتبی رو یاد بگیرید. باقی اون رو اومدن دماغش رو کج کردن و یا دهنش رو عوض کردن
سلام.
لطفا اگر ممکن است الگوریتم ( Clustering using Representatives) (CURE) رو هم توضیح بدین. یا برای کد متلب آن راهنمایی بفر مایید واقعا بهش احتیاج دارم.
خیلی ممنون از لطف شما...
سلام و وقت بخیر
وقتی دیدم سوالتون رو سه جای مختلف سایت مطرح کردید فکر کردم رنج زیادی کشیدید. متاسفانه با این الگوریتم اشنا نبودم و بخاطر فورس بودن قضیه در گوگل جستجو کردم
اولین مطلب مربوط به ویکی پدیا بود که فکر کنم کار شما رو راه بندازه
داستان مربوط به مشکلات فرمولی هست که روش های خوشه بندی مثل کامیانه در خوشه بندیهاشون باهاش روبرو میشن.
این الگوریتم یه الگوریتم سلسله مراتبی هست. توی الگوریتم های سلسله مراتبی یکسری مرکز انتخاب میشه و با روش های مختلف اعضا دور مراکز جمع میشن. بعد عمل مرج انجام میشه.
پس کلیت کار شبیه اینه
از طرفی تو ویکی پدیا شبه کدش رو نوشته. کافیه بزاریدش جلوتون و شروع به پیاده سازی کنید.
مثلا گفته نقطه اولیه در نظر بگیرید. خیلی راحت اول دیتاستتونو بخونید بعد با دستور رندم تو متلب یا پایتون یا سی شارپ یا r اون رو اماده کنید
من الگوریتم های زیادی پیاده سازی کردم و همیشه از همین روش استفاده کردم. شبه کد رو گذاشتم جلوم و شروع کردم
اگر وقت ندارید می تونید به ما بسپارید تا هم داکیومنت کامل و هم اموزش انلاین و هم خود کد رو تقدیم شما کنم
سلام وقتتون بخیر.عذر میخوام یه مقاله براکارم استفاده کردم که ازروش واریانس گیری برای خوشه بندی استفاده شده:دنبال یه روش خوشه بندی هستم که عملکردش بهتر باشه و بیس ریاضی قوی ای داشته باشه.حالا یاازنظر دقت یا سادگی و یا...........
با سلام
ابتدا ببینید مقاله مورد نظرتون در چه حوزه ای خوشه بندی میکنه. مثلا خوشه بندی نود های گراف؟ خوشه بندی کاربران سایت؟ و ...
حالا که متوجه شدید کافیه یه سرچ ساده بکنید. مزایا و معایبش رو پیدا کنید. احتمالا توی سرچ ها گفتن چه زمانی از فلان مدل خوشه بندی مبتنی بر گراف استفاده کنید خوبه کجا بده. اینطوری به یه اشراف کلی میرسید. حالا تنها راهی که دارید ریسکه.
انتخاب کنید و روی مجموعه دادتون پیادش کنید و با مقاله پایه مقایسه کنید. اگر بهتر شد که درست حدس زدید و اگر بهتر نشد مجبورید یه روش دیگه رو امتحان کنید که محتمل تره.
شاید هم تصمیم بگیرید یک روش غیر خوشه بندی گراف رو وارد حوزه خوشه بندی گراف کنید. اینطوری باز هم ریسکه. ولی باید ریسک رو قبول کنید. بنظرم نمی تونید شخصی رو پیدا کنید که بهتون در خصوص خوشه بندی پیشنهاد درستی بده
سلام
یک سوال دارم اگر من بخوام خوشه بندی سلسله مراتبی رو در یک شبکه ی شهری انجام بدم به چه صورت میشه؟
درواقع من شبکه ای از شهرهای دو استان تهران و البرز رو در ژوپیتر با کدنویسی پایتون ترسیم کرد و جریان جابجایی بار بین هر یک از مراکز رو تحت عنوان یال مشخص کردم و الان میخوام ببینم که چه شهرهایی با هم یک خوشه تشکیل میدن
ممنون میشم راهنمایی کنید
سلام و وقت بخیر هر شبکه شامل یک سری نود می باشد کافیست آنرا به داده تبدیل کنید داده متنی به زبانهای مانند رپیدماینر و غیره بدهید تا برای شما خوشه بندی متنی انجام دهد دوباره آن را به نرم افزارهای مربوطه دهید تا برای شما ویژوالایزر کند این یک راه دیگر این است که از نرم افزارهای مانند نود اکسل استفاده کنید تا برای شما خوشه بندی های انجام دهند مانند خوشه بندی شولت که در نود اکسل وجود دارد
سلام . چرا سایت وقتی گزینه (بیشتر ) کلیک میکنم چیزی نمیاره؟؟
با سلام
با واحد فنی مطرح شده و در حال اصلاح می باشد
سلام
جدول هایی که گفته شده در متن چرا در سایت دیده نمیشود ؟