


توضیحات:
ابتدا توضیح کلی فارغ از پیاده سازی کار به قرار زیر می باشد :
هدف شناسایی الگوی مصرف مواد غذایی می باشد.
انتخاب کلمات کلیدی و هشتگها
استخراج داده (داده ها به صورت روزانه در فرمت نودایکسل گرفته می شوند، در حال حاضر حدود یک ماه داده وجود دارد).
پیش پردازش داده
• تصفیه کردن متن: حذف علامت ها، Stop wordها، کاراکترهای دارای نویز، گرامر، توییت های غیر انگلیسی و اختصارات غیر رسمی
• شمردن تعداد وضعیت ها توسط Automatic word Count(healthy و unhealthy)(breakfast، lunch، dinner) مثلا در توییت هایی که برچسب healthy دارند کلماتی که وجود دارند شمارش می شوند.
تصور کنید بیشترین کلمات تکرار شده فست فود، غذای خانگی، ….. باشند. از تعداد این کلمات استفاده میکند و بردار ویژگی برای هلثی را میسازد.
به صورت خلاصه ابتدا داده ها به صورت کامل در نرم افزار SQL و بعد در نرم افزار رپیدماینر پیش پردازش می شوند و این پیش پردازش به صورت کامل توضیح داده می شود. تصویر زیر بخشی از این عملیات را نمایش می دهد.
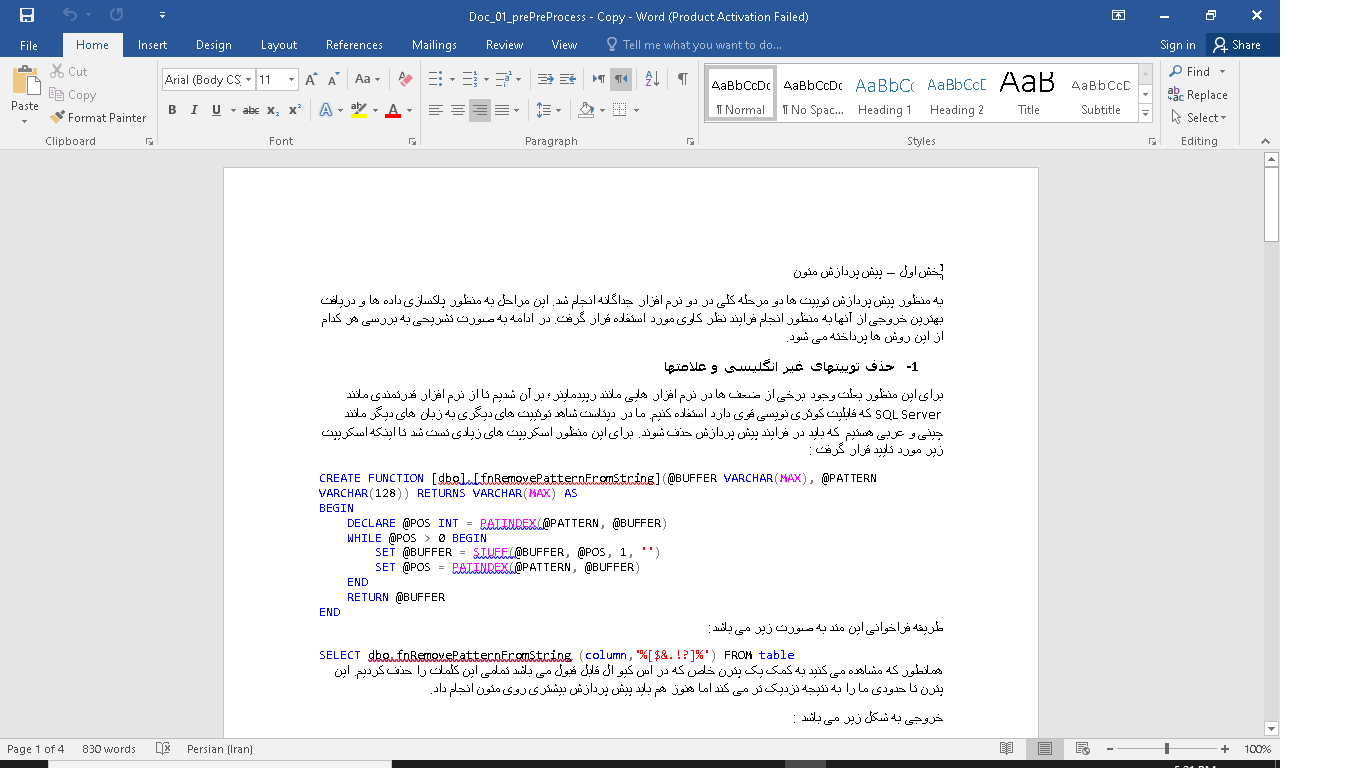
مراحل پیش پردازش در نرم افزار SQL به قرار زیر می باشد :
- حذف توییت های غیر انگلیسی
- حذف کلمات غیر انگلیسی و علایم
- حذف علامت های تایید(Accent)
- حذف هشتگ ها
- حذف حروف اضافه یا کاراکترهای دارای نویز
- حذف توییت های بی ارزش
- حذف توییت های تکراری
- تبدیل کلمات به حروف کوچک
- تغییر شکل کلمات با ارزش
کد SQL پس از خرید قابل دریافت می باشد.
پس از پیش پردازش در SQL نوبت به پیش پردازش در رپیدماینر می رسد. مراحل زیر به صورت کامل شرح و بسط و توضیح داده می شود :
خواندن اطلاعات از SQL و ورود به RapidMiner
تبدیل متون توییت ها به صفت ها
پردازش کامل متون
توکنیزه کردن اطلاعات
حذف ایست واژه ها یا Stop Words
ریشه یابی کلمات (Stem)
حذف توکن های بی ارزش
استخراج N-gram
استخراج تعداد توکن ها
حال نوبت به مدلسازی می رسد:
در بخش مدلسازی بر روی کراس ولیدیشن کار می کنیم.
همچنین از انواع و اقسام روش های مهم و مختلف جهت بهبود عملکرد مدل و افزایش صحت کار استفاده می کنیم. از الگوریتم ژنتیک به جهت بهبود عملکرد مدل استفاده می کنیم.
برخی از این روش ها شامل KNN , RF , SVM و ترکیب آنها با ژنتیک و می باشد. داکیومنت کاملا مصور و حرفه ای می باشد و در سه بخش اصلی تقسیم بندی شده است.
بطور کلی ما در این پروژه قصد داریم به پیش بینی سالم یا ناسالم بودن مواد غذایی بر اساس کامنت های مردم بپردازیم.
این پروژه تز کارشناسی ارشد می باشد که با موفقیت دفاع شده است
محتوی فایل: فایل دیتاست بعلاوه سه عدد داکمیومنت کامل از تمامی مراحل کار Doc_01_SQL Preprocessing و Doc_02_prePreProcess_in_Rapid و Doc_03_Classification و همچنین نه عدد مدل رپیدماینر از تمام مدل های انجام شده. کدهای پیش پردازش SQL نیز موجود است

دیدگاهها (0)
نقد و بررسیها
هیچ دیدگاهی برای این محصول نوشته نشده است.